
How to use LLM as a Judge for Data Validation
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaWhy Use an LLM as a Judge?
While building our platform for automating unstructured data workflows, we faced an interesting technical challenge: How can we efficiently validate output data across diverse domains, formats, and types? Rule-based validation systems are effective at catching obvious errors, but struggle with context-dependent issues. LLMs offer a promising solution.
With their nuanced understanding of language and context, LLMs can evaluate data quality in ways that closely mimic human judgment.
Our goal was to combine traditional checks with the contextual understanding of LLMs into a hybrid approach as illustrated below.
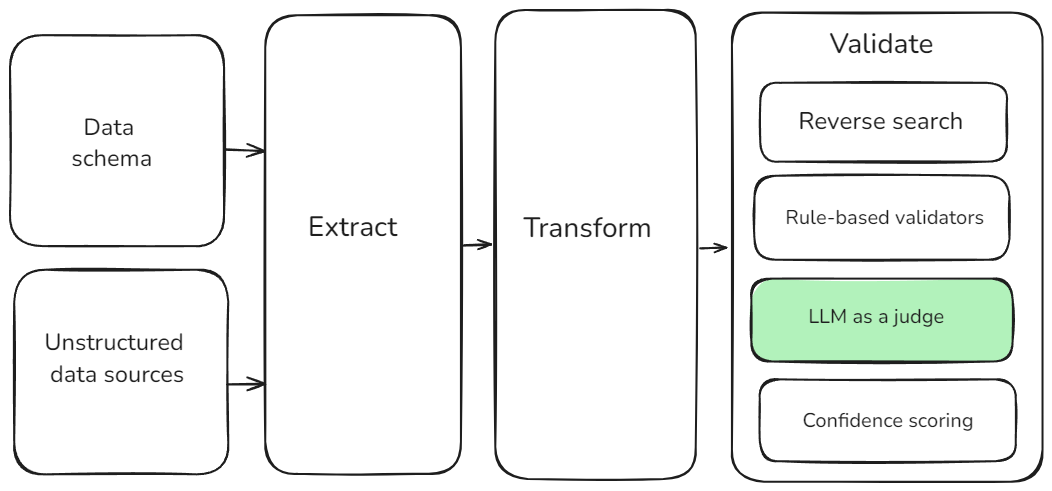
Implementing LLM as a Judge
Here's a step-by-step guide to implementing an LLM-as-a-judge system:
- Define Your Evaluation Criteria
- Start by clearly defining what you're validating. In our case, we use the following criteria:
const criteria = {
coherence:
"Evaluate the overall structure and logical format of the output data.",
consistency: "Check for factual alignment and consistency across records.",
accuracy:
"Assess how well the output matches the schema and follows the pattern of the expected data.",
completeness:
"Ensure all required fields are present and populated appropriately.",
};
- Prepare your inputs you'll need
- The data to be validated
- A schema or structure definition
- A reference answer (if applicable)
- Prompt engineering
The prompt is crucial and should include:
- Clear instructions
- The evaluation criteria
- All necessary reference materials
- Implement the validation function
Here's a simplified version of our implementation:
async function evaluateOutput(llmOutput, schema, referenceAnswer) {
// Construct prompt
// Make API call to LLM
// Parse and return the response
}
- Add consistency checks
To ensure reliability, implement a consistency check that runs multiple evaluations and checks for consistency:
- Interpret and act on results
Use the output to make decisions about your data's validity and quality.
Sample result:
{
"link": "https://www.kadoa.com/workflow/XYZ",
"duration": 164.236,
"result": {
"coherence": {
"pass": true,
"explanation": "The data is structured as an array of objects, each containing the required fields. The format is consistent across all entries, maintaining a logical and readable structure."
},
"consistency": {
"pass": true,
"explanation": "The data is consistent in terms of field types and expected content. Each entry follows the same pattern, and there are no discrepancies in the data format or logical flow."
},
"accuracy": {
"pass": false,
"explanation": "While most fields match the expected data types, the 'author' field in one entry is empty, which does not align with the schema's expectation of a non-empty string. This affects the accuracy of the data."
},
"completeness": {
"pass": false,
"explanation": "All required fields are present in each entry, but the 'author' field is not populated in one entry, which violates the requirement for all fields to be appropriately populated."
}
}
}
Binary Scale vs Numeric Scores
We first started with numeric scores (e.g. 1-10 scales) for each criterion and ran systematic tests on various LLMs with injected controlled errors into data. We then asked the model to output a numeric score reflecting error severity. Instead of a smooth, predictable gradient, the scores clustered randomly.
The distributions also varied wildly between different models or even different score ranges (e.g., -1 to 1, 0 to 1, or 1 to 10).
While numeric scores offer more granularity, the first experiments showed many limitations:
-
Inconsistency: LLMs often struggle to maintain consistent interpretations of numeric scales across different evaluations. The distribution was usually very uneven.
-
Reasoning limitations: LLMs may have difficulty justifying small differences between close numeric scores (e.g., 7 vs 8).
-
Calibration issues: Calibrating a consistent numeric output across models and ranges seems very challenging as LLMs interpret scoring instructions differently. A model might label everything 10 (“worst”) despite small differences in error rates.
In contrast, a binary scale (pass/fail) is less ambiguous, more consistent across evaluations, and easier to interpret and compare.
Improving Numeric Scoring
Numeric scoring might become more reliable if you:
- Provide a clear explanation (or “map”) for every score and define what each score threshold means in precise language.
- Have the model generate a written explanation first, then derive the numeric score from that explanation. This “chain-of-thought” approach can improve consistency.
Numeric scoring is tempting but often less stable for production use. A binary pass/fail approach is more robust unless you invest the time into meticulously defining and testing numeric thresholds for a specific domain.
Best Practices and Considerations
- Use a Binary Scale: We've found that a pass/fail system for each criterion leads to more consistent results than nuanced scales.
- Provide Detailed Reference Materials: The more context you give the LLM, the more accurate its judgments will be.
- Balance Temperature: A lower temperature tends to produce more consistent scoring results, but usually leads to less meaningful feedback.
- Implement Error Handling: LLMs can occasionally produce unexpected outputs, so robust error handling is crucial.
- Hybrid Approaches: Integrating LLM judges with traditional rule-based systems for hybrid approaches
What's Next?
We were able to improve our data validation, improve error detection, and reduce data cleaning time. We'll continue to refine our use of LLMs as judges and might even fine-tune the models on domain-specific data to improve accuracy further.

Adrian is the Co-Founder and CEO of Kadoa. He has a background in software engineering and AI, and is passionate about building tools that make data extraction accessible to everyone.
Related Articles

Introducing Self-Healing Web Scrapers
Traditional rule-based scrapers often break when the source website changes. Kadoa solves this challenge with AI.

Real-Time Tenant Profile Tracking with Kadoa
How investors use Kadoa to extract and monitor tenant directories across Simon Property Group's 300 premium shopping destinations.

What is Web Scraping? Enterprise Use Cases for 2026
A comprehensive enterprise guide to web scraping in 2026. How to run it at scale, where AI helps, how to stop losing engineering hours to maintenance, and what separates platforms worth evaluating.