
AI Agents: Hype vs. Reality
 Adrian Krebs,Co-Founder & CEO of Kadoa
Adrian Krebs,Co-Founder & CEO of KadoaThe promise of autonomous AI agents that can perform complex tasks has generated a lot of excitement. By interacting with external tools and functions, LLMs can carry out multi-step workflows without human intervention.
But reality is proving more challenging than anticipated.
The WebArena leaderboard, which benchmarks LLM agents against real-world tasks, shows that even the best-performing models have a success rate of only 45.7%.
What is an AI agent?
The term "AI agent" isn't really defined, and there seems to a lot of controversy about what an agent even is. An AI agent can be defined as an LLM that is given agency (usually function calling in RAG setting) to make high-level decisions about how to perform tasks in an environment.
There are two main architectural approaches to building AI agents:
-
Monolithic agents: A single large model handles the entire task and makes all decisions and actions based on its full context understanding. This approach leverages the emergent capabilities of large models and avoids information loss from dividing the task.
-
Multi-agent systems: The task is broken down into subtasks, each handled by a smaller, more specialized agent. Instead of trying to have one large general purpose agent that is hard to control and test, we can use many smaller agents that basically just pick the right strategy for a specific sub-task. This approach is sometimes necessary due to practical constraints like context window size or the need for different skillsets.
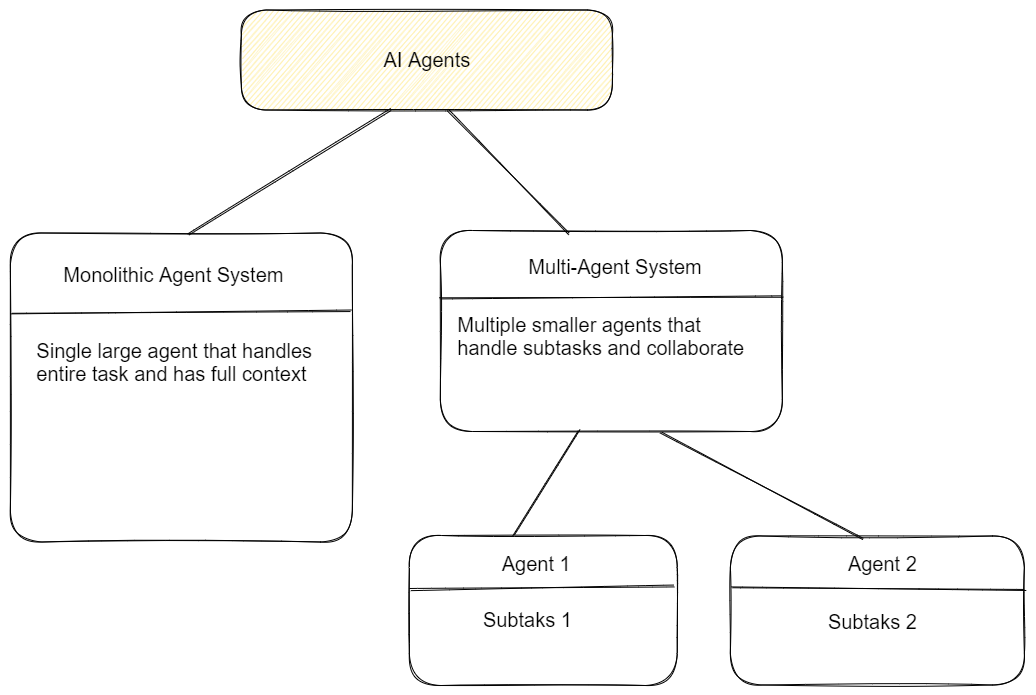
In theory, a monolithic agent with infinite context size and perfect attention would be ideal. Multi-agent systems will always be less effective than monolithic systems on a given problem because of less context. Individual agents work best when they have entirely different functionalities.
One great summary comes from this HackerNews comment by an OpenAI employee:
I'd say single, big API calls are better when:
- Much of the information/substeps are interrelated
- You want immediate output for a user-facing app, without having to wait for intermediate steps
Multiple, sequenced API calls are better when:
- You can decompose the task into smaller steps, each of which do not require full context
- There's a tree or graph of steps, and you want to prune irrelevant branches as you proceed from the root
- You want to have some 100% reliabile logic live outside of the LLM in parsing/routing code
- You want to customize the prompts based on results from previous steps
Challenges in Practice
After seeing many attempts to AI agents, I believe it's too early, too expensive, too slow, too unreliable. It feels like many AI agent startups are waiting for a model breakthrough that will start the race to productize agents.
-
Reliability: As we all know, LLMs are prone to hallucinations and inconsistencies. Chaining multiple AI steps compounds these issues, especially for tasks requiring exact outputs.
-
Performance and costs: GPT-4o, Gemini-2.0, and Claude Sonnet are working quite well with tool usage/function calling, but they are still slow and expensive, particularly if you need to do loops and automatic retries.
-
Legal concerns: Companies may be held liable for the mistakes of their agents. A recent example is Air Canada being ordered to pay a customer who was misled by the airline's chatbot.
-
User trust: The "black box" nature of AI agents and stories like the above makes it hard for users to understand and trust their outputs. Gaining user trust for sensitive tasks involving payments or personal information will be hard ( paying bills, shopping, etc.).
Real-World Attempts
Several startups and incumbent players are working on general AI agents, but most are still rather experimental:
- adept.ai - $350M funding, the leadership team was recently acqui-hired by Amazon
- Runner H - $220M funding, not publicly accessible yet
- MultiOn - funding unknown, their API-first approach seems promising
- Browserbase - $27M funding, provides the infrastructure layer for autonomous browser agents. Many vertical AI startups are already relaying on them.
Only MultiOn and Browserbase seems to be pursuing the "give it instructions and watch it go" approach, which is more in line with the promise of AI agents. Many others are going down the record-and-replay RPA route, which may be necessary for reliability at this stage.
Large players are also bringing agentic capabilities to desktops and browsers, and it looks like we'll get native AI integrations on a system level:
- Claude Computer Use
- Microsoft announced Copilot Studio to build custom copilot agents
- Project Mariner from Google Deepmind offers agentic browser automations
- OpenAI will likely follow with agentic capabilities as they've rolled out their Mac desktop app that can interact with the OS screen and browser
These early tools are impressive, but we'll see how well these agent capabilities will work when released publicly and tested against real-world scenarios instead of hand-picked demo cases.
Vertical agents focus on a specific domain, such as programming, customer support, or legal tasks. Specialized agents can perform better because they rely on domain-specific fine-tuning and tools. Aside from Devin for coding, I haven't personally tried any vertical AI agents yet, but I plan to talk to domain experts and review a few of them soon.
The Path Forward
AI agents are overhyped and most of them are simply not ready for mission-critical work. However, the underlying models and architectures continue to advance quickly, and we can expect to see more successful real-world applications.
The most promising path forward likely looks like this:
- The near-term focus should be on augmenting existing tools with AI rather than offering a broad fully-autonomous standalone service.
- Human-in-the-loop approaches that keep humans involved for oversight and handling edge cases.
- Setting realistic expectations about current capabilities and limitations.
By combining tightly constrained LLMs, good evaluation data, human-in-the-loop oversight, and traditional engineering methods, we can achieve reliably good results for automating medium-complex tasks.
Will AI agents automate tedious repetitive work, such as web scraping, form filling, and data entry? Yes, absolutely.
Will AI agents autonomously book your vacation without your intervention? Unlikely, at least in the near future.

Related Articles

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Best AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.